用于异常值检测(异常检测)的全面且可扩展的 Python 库

项目描述
部署 & 文档 & 统计 & 许可证











新闻:我们刚刚发布了 36 页,最全面的异常检测基准论文。完全开源的 ADBench在 55 个基准数据集上比较了 30 种异常检测算法。
PyOD 是用于检测多元数据中的异常对象的最全面和可扩展的Python 库。这个令人兴奋但具有挑战性的领域通常被称为 异常检测 或异常检测。
PyOD 包括 40 多种检测算法,从经典的 LOF (SIGMOD 2000) 到最新的 ECOD (TKDE 2022)。自 2017 年以来,PyOD 已成功用于众多学术研究和商业产品中,下载量超过800 万次。它还通过各种专门的帖子/教程得到了机器学习社区的认可,包括 Analytics Vidhya、 KDnuggets和 Towards Data Science。
PyOD 适用于:
跨各种算法的统一 API、详细文档和交互式示例。
高级模型,包括经典的距离和密度估计、最新的深度学习方法和新兴算法,如 ECOD。
使用 SUOD [ 45 ]进行快速训练和预测。
使用 5 行代码进行异常值检测:
# train an ECOD detector
from pyod.models.ecod import ECOD
clf = ECOD()
clf.fit(X_train)
# get outlier scores
y_train_scores = clf.decision_scores_ # raw outlier scores on the train data
y_test_scores = clf.decision_function(X_test) # predict raw outlier scores on test关于选择OD算法的个人建议。如果您不知道要尝试哪种算法,请使用:
它们既快速又可解释。或者,您可以尝试更多数据驱动的方法MetaOD。
引用 PyOD:
PyOD 论文发表在 Journal of Machine Learning Research (JMLR) (MLOSS track) 上。如果您在科学出版物中使用 PyOD,我们将不胜感激引用以下论文:
@article{zhao2019pyod,
author = {Zhao, Yue and Nasrullah, Zain and Li, Zheng},
title = {PyOD: A Python Toolbox for Scalable Outlier Detection},
journal = {Journal of Machine Learning Research},
year = {2019},
volume = {20},
number = {96},
pages = {1-7},
url = {http://jmlr.org/papers/v20/19-011.html}
}
或者:
Zhao, Y., Nasrullah, Z. and Li, Z., 2019. PyOD: A Python Toolbox for Scalable Outlier Detection. Journal of machine learning research (JMLR), 20(96), pp.1-7.
关键链接和资源:
目录:
安装
建议使用pip或conda进行安装。请确保 已安装最新版本,因为 PyOD 经常更新:
pip install pyod # normal install
pip install --upgrade pyod # or update if neededconda install -c conda-forge pyod或者,您可以克隆并运行 setup.py 文件:
git clone https://github.com/yzhao062/pyod.git
cd pyod
pip install .所需的依赖项:
Python 3.6+
工作库
matplotlib
numpy>=1.19
数>=0.51
scipy>=1.5.1
scikit_learn>=0.20.0
六
统计模型
可选依赖项(请参阅下面的详细信息):
组合(可选,models/combination.py 和 FeatureBagging 需要)
keras/tensorflow(可选,AutoEncoder 和其他深度学习模型需要)
pandas(可选,运行基准测试所需)
suod(可选,运行 SUOD 模型所需)
xgboost(可选,XGBOD 需要)
警告:PyOD 有多个基于神经网络的模型,例如 AutoEncoders,它们在 Tensorflow 和 PyTorch 中都实现了。但是,PyOD 不会为您安装这些深度学习库。这降低了干扰本地副本的风险。如果您想使用基于神经网络的模型,请确保已安装这些深度学习库。提供了说明:神经网络常见问题解答。同样,依赖于xgboost的模型,例如 XGBOD,默认情况下不会强制安装 xgboost。
API 备忘单和参考
完整的 API 参考:(https://pyod.readthedocs.io/en/latest/pyod.html)。所有检测器的 API 备忘单:
fit(X):拟合检测器。y 在无监督方法中被忽略。
decision_function(X):使用拟合检测器预测 X 的原始异常分数。
predict(X):预测特定样本是否为异常值或不使用拟合检测器。
predict_proba(X):使用拟合检测器预测样本异常值的概率。
predict_confidence(X):预测模型的样本置信度(在 predict 和 predict_proba 中可用)[ 31 ]。
拟合模型的关键属性:
decision_scores_:训练数据的异常分数。越高越不正常。异常值往往具有更高的分数。
labels_:训练数据的二进制标签。0 代表异常值,1 代表异常值/异常值。
ADBench 基准
我们刚刚发布了 36 页,最全面的异常检测基准论文 [ 14 ]。完全开源的 ADBench在 55 个基准数据集上比较了 30 种异常检测算法。
ADBench的组织结构如下:

下面提供了所选模型的比较(图, compare_all_models.py, 交互式 Jupyter Notebooks)。对于 Jupyter Notebooks,请导航到“/notebooks/Compare All Models.ipynb”。
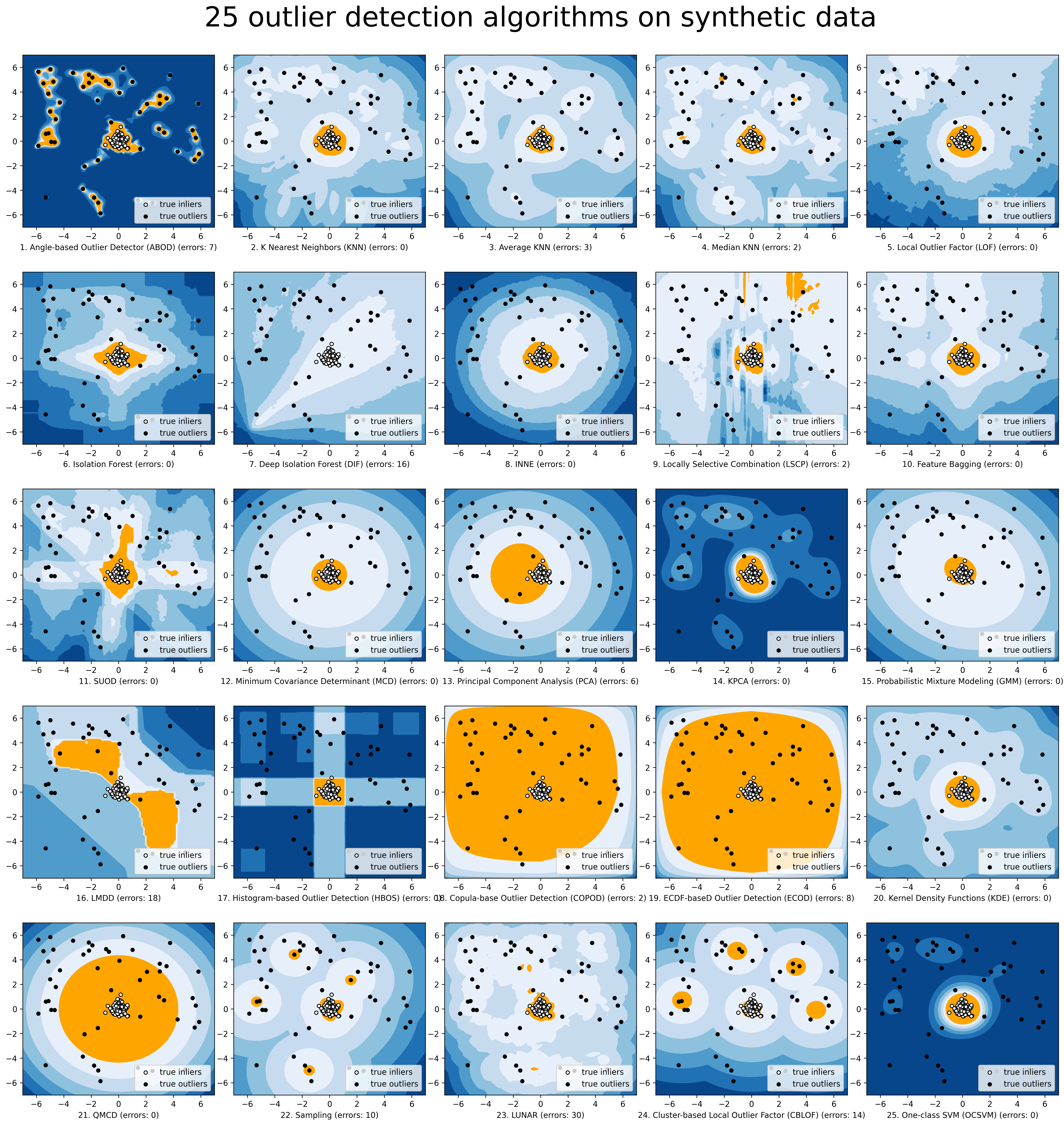
模型保存和加载
PyOD 在模型持久性方面采用了与 sklearn 类似的方法。有关说明,请参阅模型持久性。
简而言之,我们建议使用 joblib 或 pickle 来保存和加载 PyOD 模型。有关示例,请参见“examples/save_load_model_example.py”。简而言之,它很简单,如下所示:
from joblib import dump, load
# save the model
dump(clf, 'clf.joblib')
# load the model
clf = load('clf.joblib')SUOD 快速列车
快速训练和预测:通过利用 SUOD 框架[ 45 ],可以在 PyOD 中使用大量检测模型进行训练和预测。请参阅 SUOD 纸 和 SUOD 示例。
from pyod.models.suod import SUOD
# initialized a group of outlier detectors for acceleration
detector_list = [LOF(n_neighbors=15), LOF(n_neighbors=20),
LOF(n_neighbors=25), LOF(n_neighbors=35),
COPOD(), IForest(n_estimators=100),
IForest(n_estimators=200)]
# decide the number of parallel process, and the combination method
# then clf can be used as any outlier detection model
clf = SUOD(base_estimators=detector_list, n_jobs=2, combination='average',
verbose=False)实现的算法
PyOD 工具包由三个主要功能组组成:
(i) 个体检测算法:
类型 |
缩写 |
算法 |
年 |
参考 |
|---|---|---|---|---|
概率的 |
生态环境保护 |
使用经验累积分布函数的无监督异常值检测 |
2022 |
|
概率的 |
ABOD |
基于角度的异常值检测 |
2008年 |
|
概率的 |
FastABOD |
使用近似的快速基于角度的异常值检测 |
2008年 |
|
概率的 |
慢性阻塞性肺病 |
COPOD:基于 Copula 的异常值检测 |
2020 |
|
概率的 |
疯狂的 |
中值绝对偏差 (MAD) |
1993 |
|
概率的 |
求救 |
随机异常值选择 |
2012 |
|
概率的 |
KDE |
使用核密度函数检测异常值 |
2007年 |
|
概率的 |
采样 |
通过采样快速基于距离的异常值检测 |
2013 |
|
概率的 |
GMM |
用于异常值分析的概率混合建模 |
[ 1 ] [第 2 章] |
|
线性模型 |
主成分分析 |
主成分分析(到特征向量超平面的加权投影距离之和) |
2003年 |
|
线性模型 |
MCD |
最小协方差行列式(使用马氏距离作为异常值) |
1999 |
|
线性模型 |
光盘 |
使用库克距离进行异常值检测 |
1977年 |
|
线性模型 |
OCSVM |
一类支持向量机 |
2001年 |
|
线性模型 |
LMDD |
基于偏差的异常值检测 (LMDD) |
1996 |
|
基于接近的 |
LOF |
局部异常因子 |
2000 |
|
基于接近的 |
COF |
基于连通性的异常值因子 |
2002年 |
|
基于接近的 |
(增量)COF |
基于内存高效连接的异常值因子(速度较慢但降低存储复杂性) |
2002年 |
|
基于接近的 |
CBLOF |
基于聚类的局部异常值因子 |
2003年 |
|
基于接近的 |
地点 |
LOCI:使用局部相关积分进行快速异常值检测 |
2003年 |
|
基于接近的 |
高压氧 |
基于直方图的异常值分数 |
2012 |
|
基于接近的 |
神经网络 |
k 最近邻(使用到第 k 个最近邻的距离作为异常值) |
2000 |
|
基于接近的 |
平均KNN |
平均 kNN(使用到 k 个最近邻的平均距离作为异常值) |
2002年 |
|
基于接近的 |
MedKNN |
中值 kNN(使用与 k 个最近邻的中值距离作为异常值) |
2002年 |
|
基于接近的 |
草皮 |
子空间异常值检测 |
2009 |
|
基于接近的 |
竿 |
基于旋转的异常值检测 |
2020 |
|
离群值合奏 |
森林 |
隔离森林 |
2008年 |
|
离群值合奏 |
英尼 |
使用最近邻集成的基于隔离的异常检测 |
2018 |
|
离群值合奏 |
脸书 |
特征套袋 |
2005年 |
|
离群值合奏 |
LSCP |
LSCP:并行异常值集合的局部选择性组合 |
2019 |
|
离群值合奏 |
XGBOD |
基于 Extreme Boosting 的异常值检测(监督) |
2018 |
|
离群值合奏 |
洛达 |
轻量级异常在线检测器 |
2016 年 |
|
离群值合奏 |
苏德 |
SUOD:加速大规模无监督异构异常值检测(加速) |
2021 |
|
神经网络 |
自动编码器 |
全连接自动编码器(使用重建误差作为异常值) |
[ 1 ] [第 3 章] |
|
神经网络 |
VAE |
变分自动编码器(使用重建误差作为异常值) |
2013 |
|
神经网络 |
Beta-VAE |
Variational AutoEncoder(所有通过改变 gamma 和容量定制的损失项) |
2018 |
|
神经网络 |
SO_GAAL |
单目标生成对抗主动学习 |
2019 |
|
神经网络 |
MO_GAAL |
多目标生成对抗主动学习 |
2019 |
|
神经网络 |
DeepSVDD |
深度一类分类 |
2018 |
|
神经网络 |
安诺甘 |
使用生成对抗网络进行异常检测 |
2017 |
|
神经网络 |
阿拉德 |
对抗性学习异常检测 |
2018 |
|
基于图 |
R-图 |
通过 R-graph 检测异常值 |
2017 |
|
基于图 |
月球 |
LUNAR:通过图神经网络统一局部异常值检测方法 |
2022 |
(ii) 异常值集成和异常值检测器组合框架:
类型 |
缩写 |
算法 |
年 |
参考 |
|---|---|---|---|---|
离群值合奏 |
脸书 |
特征套袋 |
2005年 |
|
离群值合奏 |
LSCP |
LSCP:并行异常值集合的局部选择性组合 |
2019 |
|
离群值合奏 |
XGBOD |
基于 Extreme Boosting 的异常值检测(监督) |
2018 |
|
离群值合奏 |
洛达 |
轻量级异常在线检测器 |
2016 年 |
|
离群值合奏 |
苏德 |
SUOD:加速大规模无监督异构异常值检测(加速) |
2021 |
|
离群值合奏 |
英尼 |
使用最近邻集成的基于隔离的异常检测 |
2018 |
|
组合 |
平均 |
通过平均分数的简单组合 |
2015 |
|
组合 |
加权平均 |
通过平均分数与检测器权重的简单组合 |
2015 |
|
组合 |
最大化 |
取最高分的简单组合 |
2015 |
|
组合 |
AOM |
最大值的平均值 |
2015 |
|
组合 |
恐鸟 |
平均最大化 |
2015 |
|
组合 |
中位数 |
通过取分数的中位数进行简单组合 |
2015 |
|
组合 |
多数票 |
通过对标签的多数投票进行简单组合(可以使用权重) |
2015 |
(iii) 实用功能:
类型 |
姓名 |
功能 |
文档 |
|---|---|---|---|
数据 |
生成数据 |
综合数据生成;正常数据由多元高斯生成,异常值由均匀分布生成 |
|
数据 |
generate_data_clusters |
集群中的合成数据生成;可以使用多个集群创建更复杂的数据模式 |
|
统计 |
wpearsonr |
计算两个样本的加权皮尔逊相关性 |
|
效用 |
获取标签n |
通过将 1 分配给前 n 个异常值分数,将原始异常值分数转换为二进制标签 |
|
效用 |
Precision_n_scores |
计算精度@rank n |
异常值检测快速入门
PyOD 通过一些特色帖子和教程得到了机器学习社区的认可。
Analytics Vidhya:使用 PyOD 库在 Python 中学习异常值检测的精彩教程
KDnuggets : Intuitive Visualization of Outlier Detection Methods , An Overview of Outlier Detection Methods from PyOD
迈向数据科学:傻瓜异常检测
计算机视觉新闻(2019 年 3 月):用于异常值检测的 Python 开源工具箱
“examples/knn_example.py” 演示了使用kNN检测器的基本API。请注意,所有其他算法的 API 都是一致/相似的。
运行示例的更详细说明可以在示例目录中找到。
初始化一个 kNN 检测器,拟合模型并进行预测。
from pyod.models.knn import KNN # kNN detector # train kNN detector clf_name = 'KNN' clf = KNN() clf.fit(X_train) # get the prediction label and outlier scores of the training data y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers) y_train_scores = clf.decision_scores_ # raw outlier scores # get the prediction on the test data y_test_pred = clf.predict(X_test) # outlier labels (0 or 1) y_test_scores = clf.decision_function(X_test) # outlier scores # it is possible to get the prediction confidence as well y_test_pred, y_test_pred_confidence = clf.predict(X_test, return_confidence=True) # outlier labels (0 or 1) and confidence in the range of [0,1]通过 ROC 和 Precision @ Rank n (p@n) 评估预测。
from pyod.utils.data import evaluate_print # evaluate and print the results print("\nOn Training Data:") evaluate_print(clf_name, y_train, y_train_scores) print("\nOn Test Data:") evaluate_print(clf_name, y_test, y_test_scores)查看示例输出和可视化。
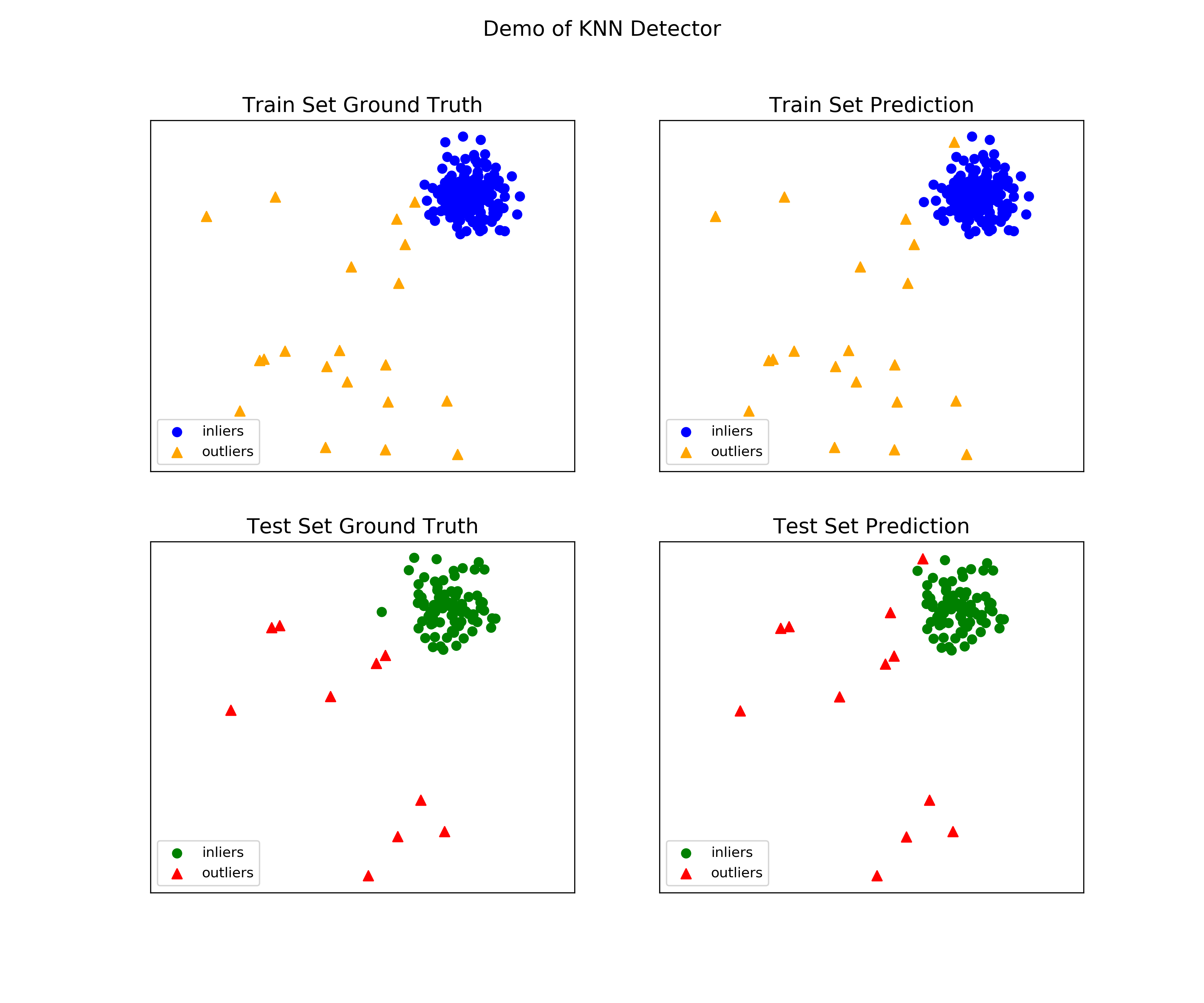
On Training Data: KNN ROC:1.0, precision @ rank n:1.0 On Test Data: KNN ROC:0.9989, precision @ rank n:0.9visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred, y_test_pred, show_figure=True, save_figure=False)
可视化(knn_figure):
如何贡献
欢迎您为这个令人兴奋的项目做出贡献:
请首先检查问题列表中的“需要帮助”标签并评论您感兴趣的问题。我们会将问题分配给您。
分叉主分支并添加您的改进/修改/修复。
向开发分支创建拉取请求并遵循拉取请求模板PR 模板
将触发自动测试。确保通过所有测试。请确保所有添加的模块都带有适当的测试功能。
为确保代码具有相同的样式和标准,请参考 abod.py、hbos.py 或 feature_bagging.py。
也欢迎您通过打开问题或发送电子邮件至zhaoy @ cmu来分享您的想法。教育:)
纳入标准
与scikit-learn类似,我们主要考虑完善的包含算法。经验法则是自出版以来至少两年,被引用超过 50 次,并且有用。
However, we encourage the author(s) of newly proposed models to share and add your implementation into PyOD for boosting ML accessibility and reproducibility. This exception only applies if you could commit to the maintenance of your model for at least two year period.